Implementing and Experimenting with the Multiscale Multi-head Self-attention Ensemble Network for cancer detection
Introduction
Breast cancer is the most diagnosed cancer and one of the leading cancer-related deaths among women. Through a process called digital pathology scanning, whole Slide Images (WSIs) are acquired recording potentially cancerous tissue at very high resolution. Skilled physicians are able to make a diagnosis based on examining these images. By leveraging deep learning techniques, this process can be assisted or even automated, making diagnosis faster, more cost-effective, and more consistent while helping physicians focus their expertise on the most challenging cases.
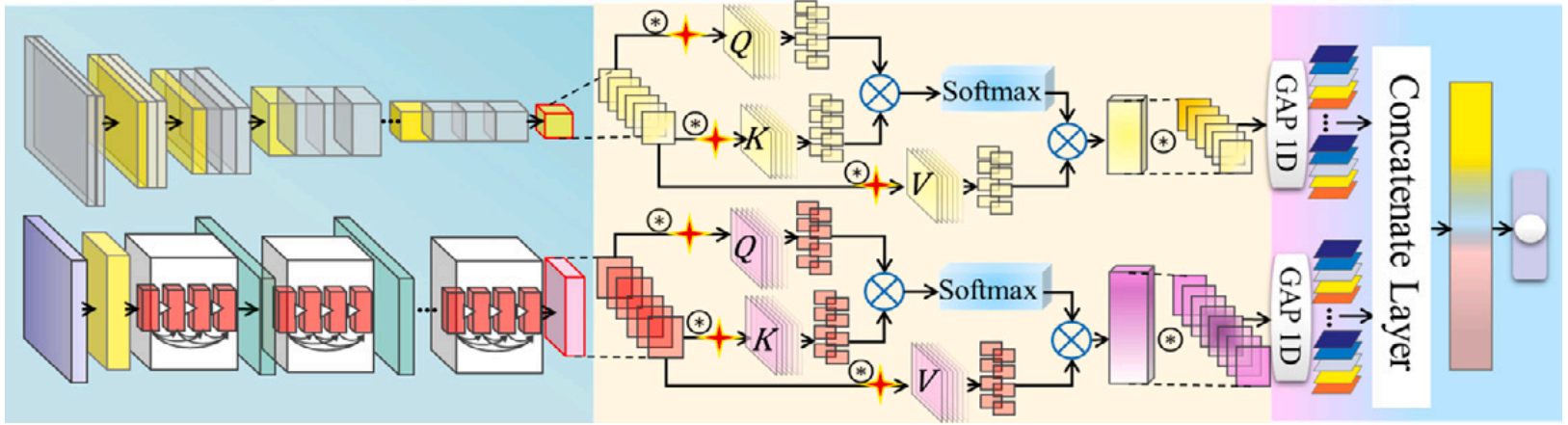
R. Ge et al. propose the Multiscale Multi-head Self-attention Ensemble Network (MMSEN). It is a heterogeneous deep ensemble learning approach. Ensemble techniques show good generalization capabilities. The intermediate feature vectors produced by VGG16 and DenseNet121, pretrained on the ImageNet1k dataset, are combined using a self-attention layer, followed by global average pooling.
Due to a scarcity of data the authors of the original paper use a five-fold cross validation, to train and assess the models performance. Here we simply split the data into disjoint train, test and evaluation sets. This may be the reason for the large deviation in the results reported by R. Ge et al. and the results we show here.
We train the model on the PCam benchmark dataset, while the model achieves high precision and specifity, the sensitivity is very low and even degrades further during training. This is due to an unsettling high number of false negatives. That is patients for whom the cancer would have been remained undetected. In order to mend this problem we experiment with different data augmentation and regularization techniques, to improve sensitivity.
Model Architecture
The MMSEN architecture employs two deep convolutional backbone networks, VGG16 and DenseNet121, from which intermediate feature representations are extracted. For VGG16, these features have dimensions , while for DenseNet121 they have dimensions . The spatial dimensions are then flattened and treated as a sequence, enabling the use of self-attention. Global average pooling is subsequently applied to reduce the feature representation to a compact vector. Finally, this vector is passed through a linear layer that maps it to a scalar logit, followed by a sigmoid activation to obtain the predicted probability.
Model Training and Evaluation
The model is trained on the PCam benchmark dataset, a binary classification task, images are labeled as 1 if cancerous tissue is present, 0 else. The dataset comprises 400 WSIs from Radboud University Medical Center (RUMC) and University Medical Center Utrecht (UMCU). The dataset underwent expert pathological analysis for the extraction and labeling of diagnostic patches. The WSIs are split into patches of size resulting in a dataset with 327,680 instances.
The models are trained for 10 epochs. As a loss function Binary Cross Entropy (BCE) is employed. Given a model and data points , the loss function is computed as follows
To update the weights of the model the Adam optimizer is employed and gradients are computed using backpropagation. The authors propose a custom learning rate schedule
where , , is the current epoch and is the overall number of epochs.
In order to assess the performance of the model we introduce four metrics, namely area under the Receiver Operating Characteristic curve, in the following abbreviated by ROC-AUC, precision, sensitivity and lastly specifity. Critical for the calculation of these metrics are the following four quantities.
The true positives (TP), that is the number of positive samples in the test set, that have been correctly classified as positive by the model.
The true negatives (TN), the number of negative samples, that have been correctly classified as negative.
The false positives (FP), the negative samples that have been falsely classified as positive by the model.
The false negatives (FN), the positive samples that have been falsely classified as negative.
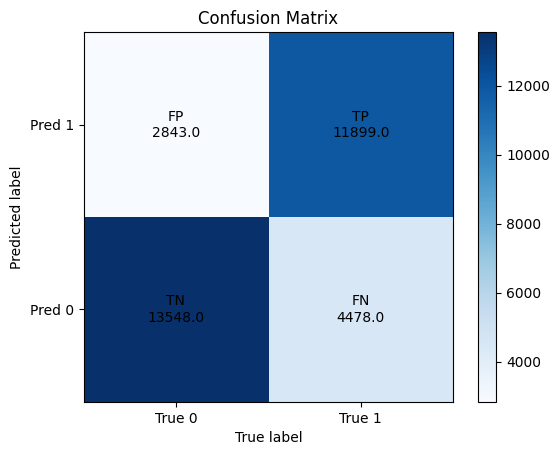
Optimally true positives and true negatives should be as high as possible, whilst false positives and false negatives should be as low as possible. These quantities are commonly visualized through a confusion matrix.
ROC-AUC measures the model’s ability to distinguish between positive and negative samples across all possible classification thresholds, a higher value indicates better separation between the two classes. Let denote the set of samples with a positive label associated to them, and those with negative label, ROC-AUC is computed as follows
Precision measures the proportion of positive predictions that are actually correct
Specificity measures the proportion of actual negative samples that are correctly classified as negative by the model. It is calculated as the number of true negatives divided by the total number of actual negative samples
Sensitivity measures the proportion of actual positive samples that are correctly identified by the model. It is calculated as the number of true positives divided by the total number of actual positive samples.
Results from base training
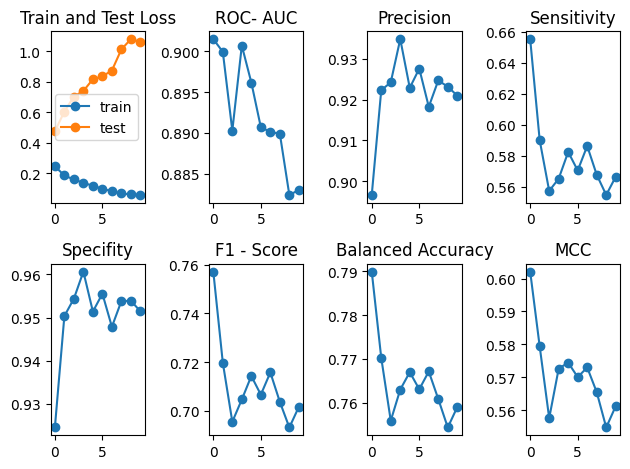
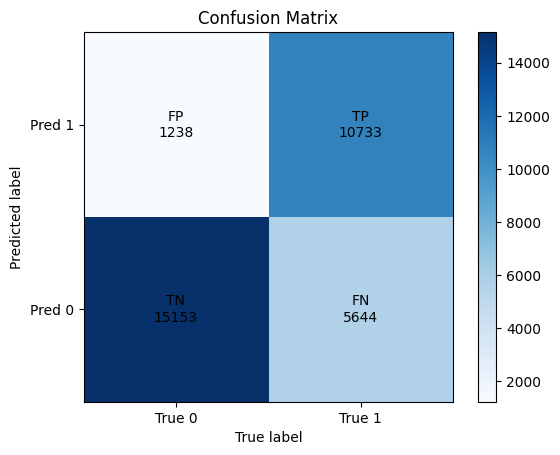
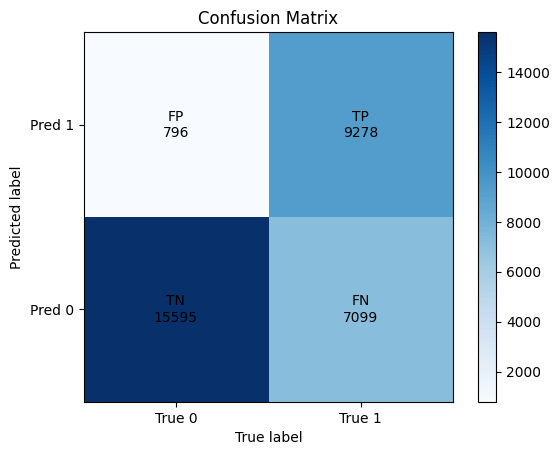
We grain the model as described in the previous section. As one can see from the graph in the top left corner, train error is decreasing over the course of training. On the other side, the test error is exploding, precision and specifity also show unstable behaviour during training, they increasing for the first couple of epochs, before falling off again. Sensitivity, as mentioned in the introduction, degrades heavily over the course of training.
In the two figures below we show the confusion matrix after one and ten epochs of training. While false positives decrease slightly and true negatives increase marginally, true positive heavily decrease and most unsettling false negatives heavily increase.
Combatting Overfitting through various Regularization Techniques
In this section we examine multiple approaches to prevent overfitting. We evaluate their success individually and finally combine methods showing an improvement to a final model.
- Data Augmentation
- Adding more Models to the assembly
- L1 & L2 weight regularization
- Lowering the learning rate
- Reducing the number of parameters
Data Augmentation
In the paper, the authors describe using random horizontal and vertical flips for data augmentation. Additionally, we incorporate random rotations of 90°, 180°, and 270°. In theory, this should not introduce any drawbacks, as the orientation of the sample under the microscope during image acquisition is arbitrary and should not affect the tissue characteristics.

The test error does not increases less drastically during training. The other metrics remain similar.
Adding more models to the assembly
Ensemble models often improve generalization because they combine predictions from multiple independently trained networks instead of relying on a single model. We want to test, whether we can improve the generalization capabilities of MMSEN by adding more more models to the assembly. To this end, we experiment with two more architectures, the AlexNet and ResNet-152. While AlexNet is smaller than both of the models employed so far, with only 8-layers, ResNet-152 comes in with 152 layers.
AlexNet is a convolutional neural network introduced by Krizhevsky et al. in 2012. The original architecture contains 8 learned layers, 5 convolutional layers followed by 3 fully connected layers. Most notably AlexNet is one of the first architectures to make use of the ReLU activation function.

ResNet-152 is a very deep convolutional neural network introduced by He et al. in the Deep Residual Learning for Image Recognition work, published around 2015. It contains 152 layers and is based on residual connections. These connections allow the network to learn residual mappings, which makes it easier to train very deep models and helps reduce the vanishing-gradient problem.

Test error and the other metrics remain unchanged. Adding more models to the assembly does not improve generalization capabilities.
Weight Regularization
Let the model parameters be denoted by , the loss with weight regularization is given by
commonly either the 1 or the 2-norm are employed to this end, is a hyperparameter. We experiment with both the 1- and the 2-norm.
For the 1 norm we used the following values . We show the results below.

For the 1-norm, choosing offers the best trade-off, while reaches the highest precision and a slightly better specifity, is solid throughout all metrics.
For the 2-norm we experimented with .

For the 2-norm we choose as it performs best for all metrics except for sensitivity.

Comparing L1- and L2-regularization, we achieve better results with the latter. Lastly comparing L2-regularization to the base model we see clear improvement in ROC-AUC as well as sensitivity, and moreover the test error stays constant during training. Unfortunately precision and specifity take a small hit.

Reducing the Learning Rate
We decrease the initial learning rate by a factor of 10, from to .

All metrics improve or either remain almost on par with the base model.
Reducing the number of Parameters
The base model has a total number of 5250561 tunable parameters. We decrease this number to only 2297601, less than half of the original size.

The metrics remain almost unchanged. Following Occam’s razor, the smaller model with less parameters should be preferred.
Final Training
We combine all the techniques which lead to an improvement to train a final model. We use data augmentation, L2-regularization with , a lowered learning rate and reduce the number of parameters.

The test error is slightly decreasing, which is a success compared to the base model, where test error is exploding. ROC-AUC is also increasing ver the first half of training before falling off very slightly and platoeing a little underneath the peak, displaying a more stable behaviour compared to the base model. Precision is oscillating to some extent and stays below the base model. Sensitivity has improved a lot, viewed independently it is still too low, more than one quarter of positive samples and remain undetected. Specificity is still high but drops below that of the base model.
Lastly we evaluate the performance of the base model and the final model on validation data. We show the resulting confusion matrices below.

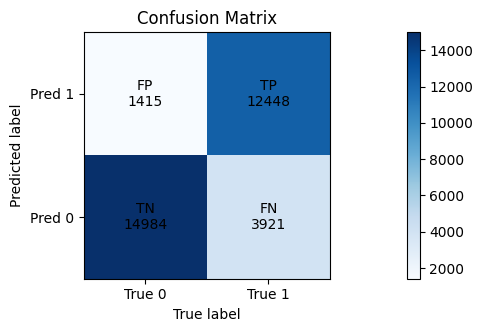
First our model also performs decently on the validation data. The picture is similar to the test data, false negatives are decreased but false positives rise and true negatives drop.
We manged to increase sensitivity while affecting precision and specifity only slightly. Still the improvement are not enough so that this model could be of use in practice.
Assessing Model Confidence and Correctness
So far, we have considered the model output only in a binary setting, each sample is classified as either negative or positive. However, the model actually returns a continuous score in the interval . We therefore want to examine whether scores closer to the extremes of this interval, that is, closer to or , correspond to more reliable predictions.
To investigate this, we evaluate the model on the evaluation set once more and partition the samples into confidence bins of width . For each bin, we compare the number of correct detections with the number of incorrect detections.


The results show that the confidence score returned by the model is informative: predictions with higher likelihood values are substantially more likely to be correct. In particular, the proportion of correct detections increases toward the upper end of the likelihood range, suggesting that the model is not only making binary decisions, but also providing a meaningful estimate of prediction confidence.